
kafka
简介
kafka是最初由LInkedin公司开发、是一个
分布式、支持分区、多副本,基于zookeeper协调的分布式消息系统,它主要是应用在日志收集系统和消息系统中。
特点
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息、它的延迟最低只有几毫秒,
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘、并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败、允许n-1个节点失败
- 高并发:支持数千个客户端同时读写
应用场景
- 日志收集:通过kafka收集各种服务的log,然后以统一服务开放给消费者
- 消息系统:解耦生产者和消费者,缓存消息等
- 运营指标:用于记录运营监控数据、包括收集各种分布式应用的数据
相关概念

Producer
Producer生产者,不断发送消息给kafka服务器,每一个生产者发送每一个消息都要有一个Topic主题
Topic
Topic主题,每一个发送到kafka的消息都会有一个主题,也可以叫做一个类别,其类似于我们传统数据库的表名一样,例如发送一个主题为log的消息,那么这个主题下就会有很多日志的消息。
Partition
Partition分区,生产者发送的消息会被Topic存储在分区中,通过分区实现负载均衡,提高kafka的吞吐量,一般分区是被分在不同的broker上也就是不同的服务器上,来保证服务的可扩展性。其中每个Topic可以指定多个分区,但是至少要指定一个,每个分区存储的数据都是有序的,不同分区之间的数据不保证有序性。
Replica
Replica副本就是每个分区中数据的备份,kafka为了防止数据丢失或者因服务器宕机而采取的保护数据完整性的措施。kafka会选择一个分区作为主分区(leader)来控制消息的读写,其他的分区都为从分区(follower),主分区会将数据同步到从分区上去。当主分区故障时会选择一个从分区来作为主分区。kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Broker
Broker是kafka的一个实例,启动一个kafka就是一个Broker,多个Broker构成一个Kafka集群。
Consumer
Consumer消费者,用于读取kafka中的消息,消费Topic的数据,每一个消费者都会有一个组名,多个消费者组成一个消费者组。
相关设计思想
- 消息状态:在kafka中,消费的状态被保存在消费者中,
Broker实例并不关系那个消息被谁消费了,它只会记录一个offset值,指向partition分区中下一个要被消费的消息位置。因此如果消费者没有处理好的话,一个消息可能会被消费多次。 - 消息持久化:kafka中会把消息持久化在本地文件系统中,并且保持极高的效率。
- push-and-pull:kafka中Producer和Consumer采用的是push-and-pull模式,就Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生存和消费是异步的。
- 同步异步:Producer采用异步Push方式,极大提高kafka系统的吞吐量。
消息队列通信模式
点对点模式
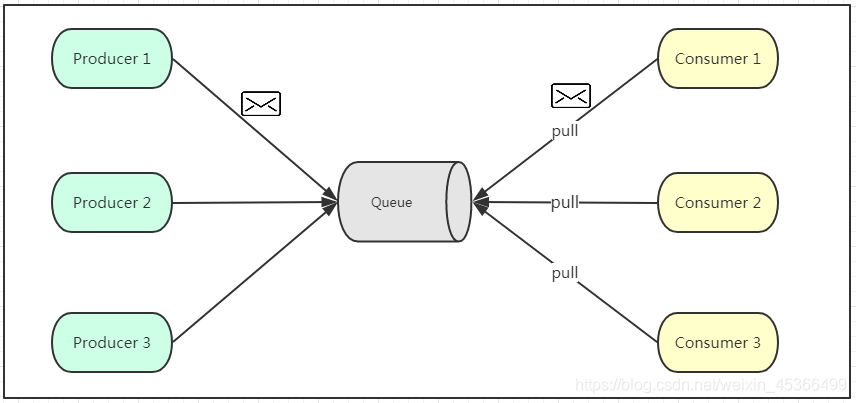
消费者通过主动拉取或者轮询的消息传送模式,这个模式的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费,好处是消费者的消费频率可以由自己控制,坏处是消费者需要额外的线程去监控消息,主动探知。
发布订阅模式
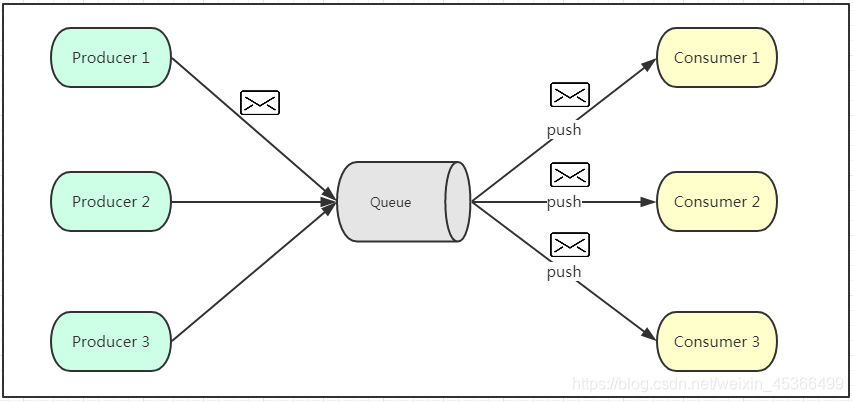
生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者,所以由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息。发布订阅模式可以由多种不同的订阅者(消费者),当各个订阅者的性能不一样时,处理消息的能力也会不一样,因此会出现资源浪费或者部分订阅者无法处理的情况。
工作流程分析
发送数据
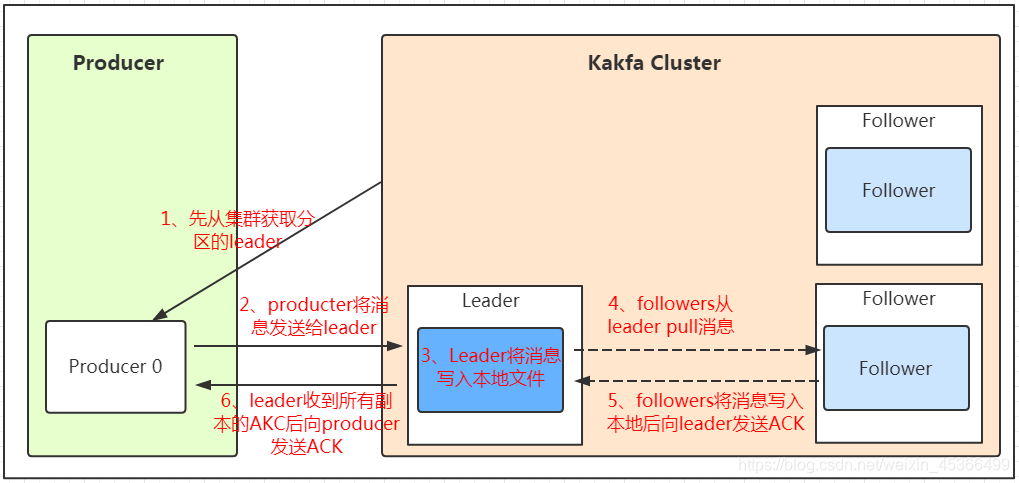
- 生产者先从
kafka集群中获得分区副本的leader - 生产者将消息发送给分区副本的
leader leader将消息写入本地文件,如果这时ack=1的话,生产者就会认为消息发送成功。否则如果为ack=-1时,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。- 这步是由其他分区副本
follwer主动从leaderpull拉取消息。 - 随后follwer将消息写入本地文件后,向
leader发送ack。 - 如上ack=2时,leader收到所有副本的ack后,发送producer给ack。
ack应答机制
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。吞吐量与可靠性的一个折中方案
- -1代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
保存数据
当生产者将数据写进对应分区里时,集群就会对数据进行保存了,kafka将数据保存在磁盘里,kafka初始会单独开辟一块磁盘空间,顺序写入数据(磁盘顺序写入会比随机效率高)。
Partition结构
分区在服务器的表现形式就是一个个文件夹,每个分区下的文件夹会有多组segment文件,每组segment文件又包含.index文件、.log文件、timeindex文件。其中.index文件和.timeindex文件是用来作为索引文件的,用于检索消息,.log文件则是用来实际存放message的地方。
message结构
在.log文件中存放了message,message主要组成的三部分是offset、消息大小、消息体。
- offset:一个占8字节的有序id号,它可以确定每条消息在partition内的位置
- 消息大小:消息大小占用4字节,用于描述消息的大小
- 消息体:消息体存放的是实际消息数据(被压缩过),占用大小根据具体消息。
存储策略
无论消息是否被消费者消费过,kafka都会保存所有的消息。在默认情况下,会保存7天内的消息或者大小在1073741824内。超过这两个条件kafka就会删除该信息。